So the usual story, the query works well for small data sets but does not work optimally for large data. What are my options ?
- Recompile the view/function/procedure
- Update states
- Add a optimize @Variable for unknown
- Look for missing indexes
- Rewrite the query
The low hanging fruits
Generally, the top two items would allow you to get over the hump but without a optimize for hint you can’t get over the parameter sniffing problem and without the index you would keep running into the same problem over and over again.
Long term
Rewrite the query to avoid the the index and if you get really lucky it may be possible to avoid the optimize for hint.
How i went about solving the problem
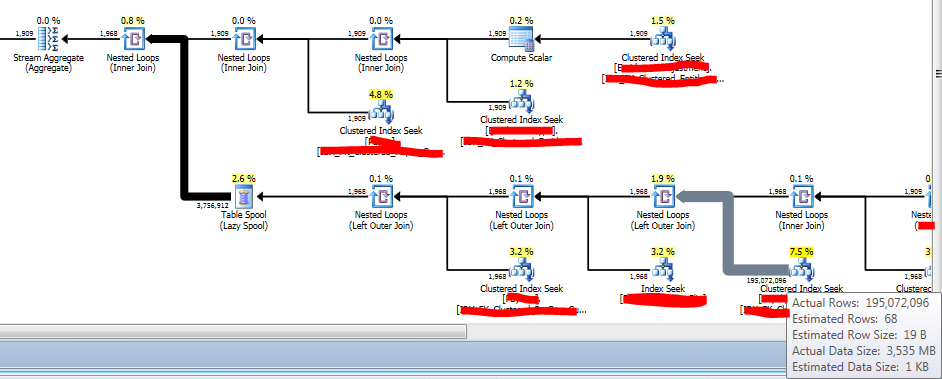
The fat line indicated where the problem existed, but what would it take to resolve the issue ? The table (let’s call it DetailTransactionLineItem just because it held detail to detail table ) had only fraction of the data for the @Pratmerter Used.
Currently it is pumping 195 million records (3.3 Gb of data) :), where in reality it only had 99K records.
Sample of the query ( is not the real query and lot less complex)
Select T2 .TranT2ID
, Sum(T2.Amount) tranAmount
, Count(T3R.TranT3RetrunID) ReturnAmountCount
From Customer C
JOIN Transaction T ON C.CustomerID = T.CustomerID
JOIN DetailTransaction T2 ON T2.TranID = T.TranID
left JOIN DetailTransactionLineItem T3 ON T3.TranT2ID = T2.TranT2ID and
C.CustomerID =T3 .CustomerID
left JOIN DetailTransactionLineItemReturn T3R ON T3R.TranT3RetrunID = T3.TranT3RetrunID
where C.CustomerID = @CustomerID
Just to get the records right, i tried all five option and nothing helped.
Steps followed
- Did record count of “DetailTransactionLineItem “ and found the table had 99000 records
That suggested there was too many moving parts that caused the optimiser to not calculate the statistics correctly. This could be observed where the estimator thinks it had only 68 records.
- Rewrote the query to loop through the T3.TranT2ID to get the ReturnAmountCount ( anded the required index ) but no luck. it still continued to pull the 195 Million records.
It now looks like the table needs a redesign with little hope.
- Then it occurred, the nest loop operator was definitely not the iterator for the job. Out of desperation the left join was changed to “Left hash join”. Wohooooo it worked in less than a half a second.
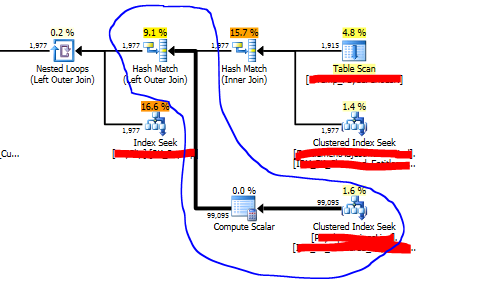
4. Now it was a matter of attempting get a good plan for data sets sitting a different percentiles.
and Obviously the has hint won’t help smaller datasets as it was a sledgehammer approach.
5. Rewrite to the query
Select T2 .TranT2ID
, Sum(T2.Amount) tranAmount
, Count(T3R.TranT3RetrunID) ReturnAmountCount
From Customer C
JOIN Transaction T ON C.CustomerID = T.CustomerID
JOIN DetailTransaction T2 ON T2.TranID = T.TranID
LEFT JOIN
(
SELECT TOP 100 PERCENT TranT3RetrunID , TranT2ID
FROM DetailTransactionLineItem T3
WHERE T3 .CustomerID = @CustomerID
) T3N ON T3N.TranT2ID = T2.TranT2ID
left JOIN DetailTransactionLineItemReturn T3R ON T3R.TranT3RetrunID = T3N.TranT3RetrunID
where C.CustomerID = @CustomerID
So it was about forcing and making the cardinality estimator get the correct information when it fails do things for it self. This was tested on SQL server 2012. Not sure if 2014 has a similar issue.
Comments
Post a Comment